时序数据库对比¶
Prometheus vs. Graphite¶
Graphite是一个用Python写的web应用,是一个企业级的系统监控工具,对硬件没有要求。它由三个软件组件组成:
- carbon 一个Twisted守护进程,监听并接收时间序列数据。
- whisper 一固定大小文件的数据库,用来存储时间序列数据,在设计上类似于RRD,RRD数据库是一个环形的数据库,你可以把它想象成表,中心处有一个指针,随着时间的变化,指针也在变,当指针指到12点处,也就是这个记录要被擦除覆盖的时候,所以它是大小固定的。总结起来,RRD 的关键词就是:环形、大小固定、无需运维、绘图。
- graphite-web 使用Django框架实现的一个webapp,它可以从whisper数据库获取时间序列数据并且进行展示。
架构图

范围
也就是说Graphite是一个被动接收的时间序列数据库,只不过提供数据展示的功能。数据采集agent、警报等其它的功能,需要引入第三方软件来支持,如StatsD。
Prometheus是一个功能非常全面的监控系统,它提供了基于时间序列数据的数据采集、存储、查询、画图和告警功能于一体。
由于prometheus采用主动 pull 采集方式的特性,它知道被监控的系统是什么样子的(哪个节点应该存在,那种时间序列模式意味着出问题),能够为问题诊断提供强力的支持。
数据模型
Graphite的metric名称以点"."分割组件,这种方式是一种维度的编码方式,通过"."来潜在的提供分割数据标识。
Prometheus除提供Metric名称之外,还可以明确的通过标签键值对标识Metric不同的维度。这种方式更易于通过查询语句来过滤、分组、匹配Metrics。
数据对比
是当Graphite和StatsD结合使用时,它存储的数据一般是聚合过后的数据(维度降低了),而不是原维度数据(这些数据有不同的维度,能够根据这些数据来定位更细节的问题)。
我们用Graphite/StatsD 统计 HTTP请求 api-server 服务的请求数,前置条件:返回码是500,请求方法POST,访问URL路径为/tracks , key返回结果如下所示:
stats.api-server.tracks.post.500 -> 93api_server_http_requests_total{method="POST",handler="/tracks",status="500",instance="<sample1>"} -> 34
api_server_http_requests_total{method="POST",handler="/tracks",status="500",instance="<sample2>"} -> 28
api_server_http_requests_total{method="POST",handler="/tracks",status="500",instance="<sample3>"} -> 31存储
Graphite存储以Whisper格式把时间序列数据存储到本地磁盘,这种数据存储格式是RRD格式数据库,其采集数据的时间间隔是固定的。任何时间序列都存储为一个单独的文件,到达采集间隔时间后新采集的数据会覆盖原有数据。
Prometheus也为每一个时间序列创建了一个本地文件,但是它允许时间序列以任意时间到达。新采集的样本被简单地追加到文件尾部,原有数据可以任意长度的时间保留。Prometheus针对短生命周期、频繁更改标签集合的时间序列的支持非常友好。
总结
Prometheus提供了一个丰富的数据模型和查询语言,而且更加容易地运行和集成到你的环境中。 如果你想要一个可以长期保留历史数据的集群解决方案,Graphite可能是一个更好的选择。
Prometheus vs. InfluxDB¶
InfluxDB是一个开源的时间序列数据库,它的商业版本具有可扩展和集群化的特性。 在Prometheus刚刚开始开发时,InfluxDB项目已经发布了近一年时间。 但是这两款产品还是有很大的不同之处,这两个系统也有一些略有不同的应用小场景。
范围
为了公平起见,我们必须把InfluxDB和Kapacitor结合起来,与Prometheus和Prometheus的报警管理工具比较。
Graphite与Prometheus的范围差异,同样适用于InfluxDB。InfluxDB也具备连续查询功能,与Prometheus的记录规则一样。
Kapacitor的作用范围相当于Prometheus的recording rules, alerting rules和警告通知功能的结合。
Prometheus提供了一个更加丰富地用于图表化和警告的查询语言,Prometheus告警器还提供了分组、重复数据删除和静默功能(silencing functionality)。
数据模型/存储
和Prometheus一样,InfluxDB数据模型采用的标签也是键值对形式,被称为tags。而且InfluxDB有第二级标签,被称为fields,不过在使用上有限制。
InfluxDB支持高达纳秒级的时间戳,以及float64、int64、bool和string的数据类型。而Prometheus仅仅支持float64的数据类型,strings和毫秒只能小范围地支持;
InfluxDB使用log-structured merge tree 的变体来存储,并提前写入日志,按时间分片。和Prometheus相比,这种存储模式更适用于事件日志,而Prometheus只支持在尾部附加数据(当时间序列数据写入的时候)。
框架
Prometheus服务之间是独立的(也就是服务之间是解藕的),核心功能(scraping, rule processing, and alerting)只依赖于本地存储。InfluxDB类似。
商业版的InfluxDB提供分布式集群存储,多节点同时支持查询(提高性能)。这说明商业版本InfluxDB很容易横向扩展,同时也意味着,你必须接受维护分布式存储的复杂性。 相比Prometheus,在运行、维护成本上更低,但在某些时候,因为场景原因,你需要明确地沿着可扩展性边界(如产品,服务,数据中心或类似方面)对服务器进行分片。 独立服务器(可以并行运行冗余)也可以为你提供更好的可靠性和故障隔离。
Kapacitor的开源版本不支持规则、警报和通知的分发/冗余功能。开源版本支持人为的扩容,类似于Prometheus。 InfluxDB提供了企业级的Kapacitor,提供一个可以支持HA/冗余功能的警报系统。
相比,Prometheus和Alertmanager提供一个完全开源,支持冗余(通过运行多个Prometheus,使用Alertmanager的高可用模式)
总结
对比两个系统之间,有诸多相似之处:
-
利用标签(Influxdb tags/ Prometheus labels)有效地支持多维度量指标。
-
使用相同的压缩算法。
-
都可扩展集成,Prometheus开源社区的友好支持,InfluxDB的商业解决方案;
-
提供API接口,允许使用第三方进行监控系统的扩展,如:统计分析工具、自动化操作等
InfluxDB优点: 适用于事件日志数据记录的场景,商业版本提供的集群方案,对于长期的时间序列存储是非常不错的,复制的数据最终一致性。
Prometheus优点: 度量指标监控,更强大的查询语言,警告和通知功能,以及第三方图形化展示软件的友好结合和警告的高可靠性和稳定性。
InfluxDB是有一家商业公司按照开放核心模式运营,可以付费提供高级功能,如:集群是闭源的,托管和技术支持。
Prometheus是一个完全开源和独立的项目,属于CNCF,同时社区活跃,很多公司在使用以及贡献者维护友好,其中也有一些二开项目提供一些商业服务和支持。
Prometheus vs OpenTSDB¶
OpenTSDB是基于HBase的分布式的、可伸缩的时间序列数据库,通过TCollector收集监控对象的各个指标,按时间的序列存入HBase中。 通过查询在一段时间内某个指标的参数,经过处理展示给用户,用户可以看到各个时间点的指标值和这段时间的变化,达到监控的目的。
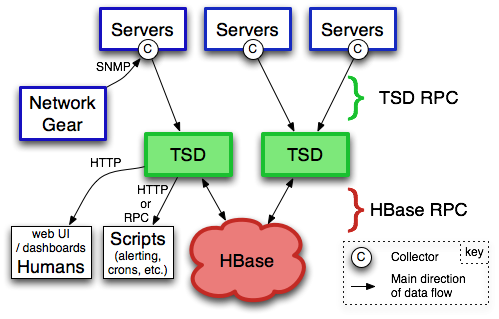
主要用途,就是做监控系统;譬如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储、查询。 存储到OpenTSDB的数据:以metric为单位的,metric就是1个监控项,譬如服务器的话,会有CPU使用率、内存使用率这些metric;
范围
和Graphite vs. Prometheus一样
数据模型
OpenTSDB的数据模型几乎和Prometheus一样:时间序列由任意的tags键值对集合表示。所有的度量指标存放在一起,并限制度量指标的总数量大小。 Prometheus和OpenTSDB有一些细微的差别,例如:Prometheus允许任意的标签字符,而OpenTSDB的tags命名有一定的限制。 OpenTSDB对查询语言支持不够完善与友好,而且API所提供的功能也只能简单地进行聚合和数学运算;
存储
OpenTSDB的存储由Hadoop和HBase实现。也就是说,在水平扩展OpenTSDB是非常容易的,但是你必须接受维护Hadoop/HBase集群的总体复杂性;
对于Prometheus,初始运行非常简单,但是如果存储的数据量达到了单节点的上限以后,需要针对Prometheus的数据架构进行改造,进行水平切分服务操作;
现在有很多Prometheus的持久化方案,比如M3DB、Chanos等
总结
Prometheus提供了一个非常灵活且丰富的查询语言,能够支持更多的度量指标数量,组成整个监控系统的一部分。 如果你对hadoop非常熟悉,并且对时间序列数据有长期的存储要求,OpenTSDB是一个不错的选择