Docker-Swarm集群监控(二)
Prometheus监控Docker Swarm集群 (二)
前面我讲解了对于Docker的一些监控知识以及Docker监控开源工具Weave Scope做了一个概述,以及简单安装。 同时也了解了Weave Scope的不足之处,而引出来了cAdvisor配合Prometheus来监控容器,本篇主要是针对Swarm集群的监控详细讲解;
Swarm简介¶
Docker Swarm 是 Docker 官方三剑客项目之一,提供 Docker 容器集群服务,是 Docker 官方对容器云生态进行支持的核心方案。
使用它,用户可以将多个 Docker 主机封装为单个大型的虚拟 Docker 主机,快速打造一套容器云平台。
注意
Docker 1.12.0以后的版本 Swarm Mode 已经内嵌入 Docker Engine,成为了 Docker 子命令 Docker Swarm,绝大多数用户已经开始使用 Swarm Mode,Docker Engine API 已经删除 Docker Swarm。
Docker 1.12 Swarm mode 已经内嵌入 Docker 引擎,成为了 docker 子命令 docker swarm。请注意与旧的 Docker Swarm 区分开来。
Swarm mode 内置 kv 存储功能,提供了众多的新特性,比如:具有容错能力的去中心化设计、内置服务发现、负载均衡、路由网格、动态伸缩、滚动更新、安全传输等。使得 Docker 原生的 Swarm 集群具备与 Mesos、Kubernetes 竞争的实力。
节点¶
运行 Docker 的主机可以主动初始化一个 Swarm 集群或者加入一个已存在的 Swarm 集群,这样这个运行 Docker 的主机就成为一个 Swarm 集群的节点 (node) 。
节点分为管理 (manager) 节点和工作 (worker) 节点。
管理节点用于 Swarm 集群的管理,docker swarm 命令基本只能在管理节点执行(节点退出集群命令 docker swarm leave 可以在工作节点执行)。 一个 Swarm 集群可以有多个管理节点,但只有一个管理节点可以成为 leader,leader 通过 raft 协议实现。
工作节点是任务执行节点,管理节点将服务 (service) 下发至工作节点执行。管理节点默认也作为工作节点。你也可以通过配置让服务只运行在管理节点。
来自 Docker 官网的这张图片形象的展示了集群中管理节点与工作节点的关系。
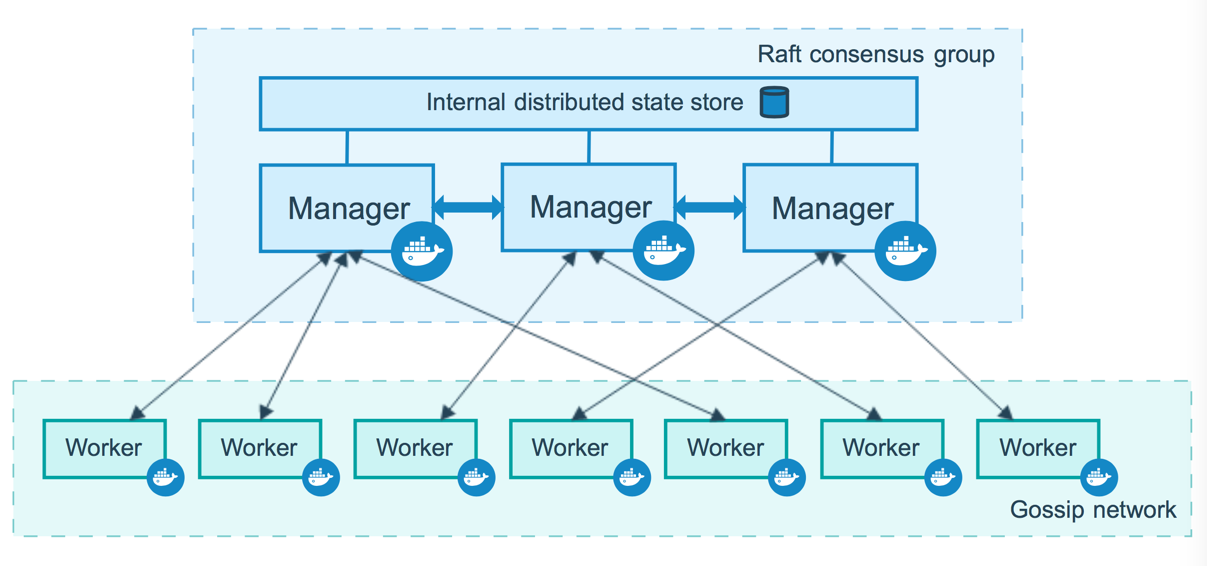
服务和任务¶
任务 (Task)是 Swarm 中的最小的调度单位,目前来说就是一个单一的容器。
服务 (Services) 是指一组任务的集合,服务定义了任务的属性。服务有两种模式:
-
replicated services 按照一定规则在各个工作节点上运行指定个数的任务。
-
global services 每个工作节点上运行一个任务
两种模式通过 docker service create 的 --mode 参数指定。
来自 Docker 官网的这张图片形象的展示了容器、任务、服务的关系。
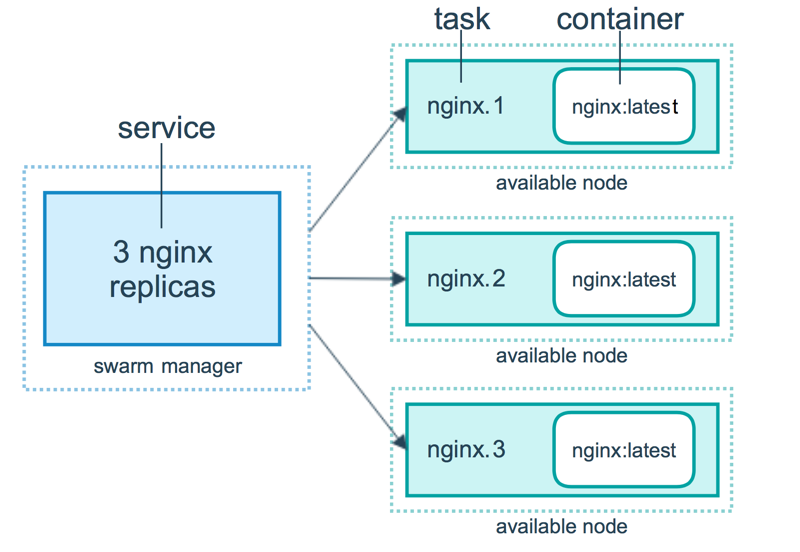
Swarm监控方案¶
一、基于cAdvisor+InfluxDB+Grafana
其中cAdvisor负责数据的收集,每一台节点都部署一个 cAdvisor 服务, Influxdb负责数据的存储, Grafana负责数据的图形可视化展示。
-
cAdvisor:数据收集模块
-
InfluxDB:数据存储
-
Grafana:图形可视化
二、基于cAdvisor+Prometheus+Grafana
通过cAdvisor将业务服务器的进行数据收集,Prometheus将数据抓取后存放到自己的时序库中,Grafana则进行图表的展现。
-
cAdvisor:数据收集模块
-
Prometheus 抓取cAdvisor收集的指标数据存储TSDB
-
Grafana:图形可视化
初始化 Swarm 集群¶
安装docker-ce,如果不指定版本,会安装最新的latest版本:
Ubuntu下查看Docker-ce版本列表 apt-cache madison docker-ce
Centos查看Docker-ce版本列表 yum list docker-ce --showduplicates | sort -r
Docker-ce 版本 19.03.11~3-0~ubuntu-bionic
基础环境:
manager: 192.168.1.220
worker01: 192.168.1.221
worker02: 192.168.1.222
apt install -y apt-transport-https software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
apt update
apt install docker-ce协议端口
TCP port: 2377 集群管理通讯
TCP and UDP port: 7946 节点之间通讯
UDP port: 4789 overlay网络流量
# 在master机器上初始化集群,运行
MASTER_IP='192.168.1.220'
docker swarm init --advertise-addr ${MASTER_IP}
# output
Swarm initialized: current node (5tk280gclbz9a4gw0k9vu9bo0) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-3lc66oda2binrl7vjfdjtf34tplt7q1bg446po6fgxasx3t48f-a05742d5tpwbkbl8r37hc9p2u 192.168.1.220:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
# 在node01 node02节点运行提示的命令加入到集群中
docker swarm join --token SWMTKN-1-3lc66oda2binrl7vjfdjtf34tplt7q1bg446po6fgxasx3t48f-a05742d5tpwbkbl8r37hc9p2u 192.168.1.220:2377
manager节点初始化集群后,都会有这样一个提示,这个的命令只是给个示例,实际命令需要根据初始化集群后的真实情况来运行。
# 在master机器上查看当前的node节点
docker node ls
root@docker-swarm-master:~# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
mnm180i3plzk2znjmdf0ded3w * docker-swarm-master Ready Active Leader 19.03.11
if8c5iltb2tau6g4v4vcccucr docker-swarm-node01 Ready Active 19.03.11
uu3jlkirrf0d5hf8bx8c5mnqc docker-swarm-node02 Ready Active 19.03.11监控Swarm集群¶
OK,Swarm集群初始化已经完成,基于cAdvisor+InfluxDB+Grafana的yaml脚本
cat docker-compose-monitor.yml
version: '3'
services:
influx:
image: influxdb
volumes:
- influx:/var/lib/influxdb
deploy:
replicas: 1
placement:
constraints:
- node.role == manager
grafana:
image: grafana/grafana
ports:
- 0.0.0.0:80:3000
volumes:
- grafana:/var/lib/grafana
depends_on:
- influx
deploy:
replicas: 1
placement:
constraints:
- node.role == manager
cadvisor:
image: google/cadvisor
hostname: '{{.Node.Hostname}}'
command: -logtostderr -docker_only -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influx:8086
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
depends_on:
- influx
deploy:
mode: global
volumes:
influx:
driver: local
grafana:
driver: local我们这里只讲第二种,基于cAdvisor+Prometheus+Grafana的方案。
git clone https://github.com/cyancow/swarmprom.git
cd swarmprom
ADMIN_USER=admin \
ADMIN_PASSWORD=admin \
SLACK_URL=https://hooks.slack.com/services/9935226 \
SLACK_CHANNEL=devops-alerts \
SLACK_USER=alertmanager \
docker stack deploy -c docker-compose.yml mon
# output
Creating network mon_net
Creating config mon_caddy_config
Creating config mon_dockerd_config
Creating config mon_node_rules
Creating config mon_task_rules
Creating service mon_prometheus
Creating service mon_caddy
Creating service mon_dockerd-exporter
Creating service mon_cadvisor
Creating service mon_grafana
Creating service mon_alertmanager
Creating service mon_unsee
Creating service mon_node-exporter
# 查看部署的stack
docker stack ls
NAME SERVICES ORCHESTRATOR
mon 8 Swarm
# 查看部署的service
docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
xnkq61woc3ag mon_alertmanager replicated 1/1 stefanprodan/swarmprom-alertmanager:v0.14.0
tzxe317tffgl mon_caddy replicated 1/1 stefanprodan/caddy:latest *:3000->3000/tcp, *:9090->9090/tcp, *:9093-9094->9093-9094/tcp
06rv2rj9oxbo mon_cadvisor global 3/3 google/cadvisor:latest
ropkluyyxora mon_dockerd-exporter global 3/3 stefanprodan/caddy:latest
29ygw9r4a92c mon_grafana replicated 1/1 stefanprodan/swarmprom-grafana:5.3.4
whqtwwmfvdjl mon_node-exporter global 3/3 stefanprodan/swarmprom-node-exporter:v0.16.0
xv19nuesymol mon_prometheus replicated 1/1 stefanprodan/swarmprom-prometheus:v2.5.0
ia2g1ayhzjf6 mon_unsee replicated 1/1 cloudflare/unsee:v0.8.0
如果想在 Swarm 部署 Portainer的话,需要在docker-compose里加入以下声明¶
...
services:
agent:
image: portainer/agent
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /var/lib/docker/volumes:/var/lib/docker/volumes
ports:
- target: 9001
published: 9001
protocol: tcp
mode: host
networks:
- net
deploy:
mode: global
placement:
constraints: [node.platform.os == linux]
portainer:
image: portainer/portainer
command: -H tcp://tasks.agent:9001 --tlsskipverify
ports:
- "8000:8000"
volumes:
- portainer_data:/data
networks:
- net
deploy:
mode: replicated
replicas: 1
placement:
constraints: [node.role == manager]
...
# 使用以下命令更新
docker stack deploy -c docker-compose.yml mon部署一个服务,然后使用Prometheus监控自动发现¶
cat test-compose.yml
version: "3.3"
networks:
net:
driver: overlay
attachable: true
mon_net:
external: true
services:
mongo:
image: healthcheck/mongo:latest
networks:
- net
deploy:
mode: replicated
replicas: 1
placement:
constraints:
- node.role != manager
mongo-exporter:
image: forekshub/percona-mongodb-exporter:latest
networks:
- net
- mon_net
ports:
- "9216:9216"
environment:
- MONGODB_URL=mongodb://mongo:27017
deploy:
mode: replicated
replicas: 1
placement:
constraints:
- node.role == manager
# 部署
docker stack deploy -c test-compose.yml mongo
# 查看 stack 列表
docker stack ls
NAME SERVICES ORCHESTRATOR
mon 10 Swarm
mongo 2 Swarm
# 查看 service 列表
docker service ls|grep mongo
o20avg5k0lqb mongo_mongo replicated 1/1 healthcheck/mongo:latest
6atp7sl2byeu mongo_mongo-exporter replicated 1/1 forekshub/percona-mongodb-exporter:latest *:9216->9216/tcp
# 在其中一个节点查看mongo是否部署成功
docker ps -a|grep mongo
102b337589aa healthcheck/mongo:latest "docker-entrypoint.s…" 18 minutes ago Up 18 minutes (healthy) 27017/tcp mongo_mongo.1.whn157ky895refdogo4s3imrw总结¶
OK,至此对于swarm集群的监控已经讲完了,对于swarm集群里,已经植入了一些简单的rules,关于Alertmanager与Rules的具体配置,在后面会在 Alertmanager告警篇幅 做详细讲解与配置。
Mesos简介¶
Mesos 最初由 UC Berkeley 的 AMP 实验室于 2009 年发起,遵循 Apache 协议,目前已经成立了 Mesosphere 公司进行运营。Mesos 可以将整个数据中心的资源(包括 CPU、内存、存储、网络等)进行抽象和调度, 使得多个应用同时运行在集群中分享资源,并无需关心资源的物理分布情况。
如果把数据中心中的集群资源看做一台服务器,那么 Mesos 要做的事情,其实就是今天操作系统内核的职责: 抽象资源 + 调度任务。Mesos 项目是 Mesosphere 公司 Datacenter Operating System (DCOS) 产品的核心部件。
Mesos 项目主要由 C++ 语言编写,代码仍在快速演化中,已经发布了正式版 1.9.0 版本。
Mesos 拥有许多引人注目的特性,包括:
-
支持数万个节点的大规模场景(Apple、Twitter、eBay 等公司实践);
-
支持多种应用框架,包括 Marathon、Singularity、Aurora 等;
-
支持 HA(基于 ZooKeeper 实现);
-
支持 Docker、LXC 等容器机制进行任务隔离;
-
提供了多个流行语言的 API,包括 Python、Java、C++ 等;
-
自带了简洁易用的 WebUI,方便用户直接进行操作。
值得注意的是,Mesos 自身只是一个资源抽象的平台,要使用它往往需要结合运行其上的分布式应用(在 Mesos 中被称作框架,framework),比如 Hadoop、Spark 等可以进行分布式计算的大数据处理应用; 比如 Marathon 可以实现 PaaS,快速部署应用并自动保持运行;比如 ElasticSearch 可以索引海量数据,提供灵活的整合和查询能力……
一般说来,如果只是用于容器集群管理,Kubernetes 更加合适,如果定制需求比较多,或者要搭建大数据平台,架构相对松耦合的 Mesos 显然更加合适。 当然,用 Mesos + Kubernetes 做容器编排也是一种可行的技术方案。需要注意,Mesos 和 Kubernetes 二者都需要团队有很强的技术实力。
从软件设计初衷来看,Kubernetes 希望成为容器管理领域的领导者,而 AWS、Azure 加入 CNCF、Docker 官方表态原生支持 Kubernetes , 说明 Kubernetes 凭借源自 Google 的优秀设计,在容器领域的地位已经不可动摇,社区和生态越来越繁荣。
Mesos 的目标则是资源共享,可以让企业把已经存在的业务负载,比如 Hadoop、Spark,放到一个共同管理的环境。
至于要不要容器化,就要看对微服务、DevOps 的需求了。
来自Mesos官方的架构图
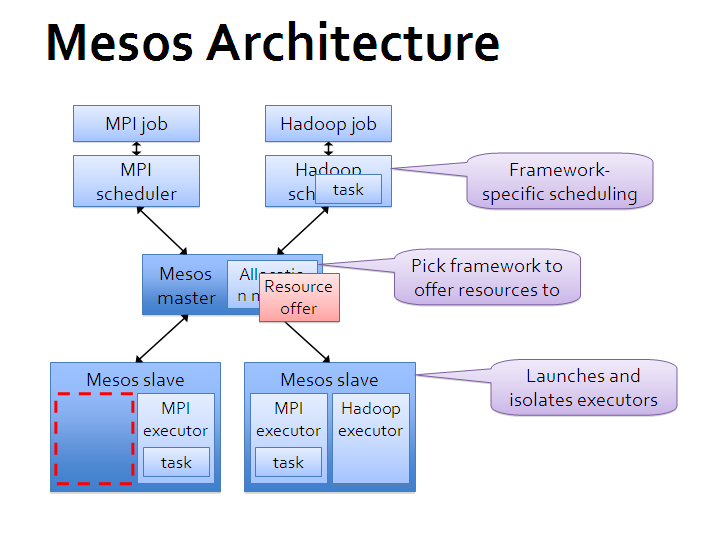
可以看出,Mesos 采用了经典的主-从(master-slave)架构,其中主节点(管理节点)可以使用 zookeeper 来做 HA。
Mesos master 服务将运行在主节点上,Mesos slave 服务则需要运行在各个计算任务节点上。
负责完成具体任务的应用框架们,跟 Mesos master 进行交互,来申请资源。
Mesos监控方案¶
针对Mesos的监控稍微有些不一样,在一开始cAdvisor设计之初只是针对Docker Host,并没有把Mesos考虑进来,cAdvisor 用 Docker Name(docker ps获取到的信息)来标记抓取的指标数据, 而 Mesos 是用 Task ID(Mesos UI和Metrics中可以看到)来标记正在运行的任务。Mesos Task的类型可以是Docker,也可以是其他。 Mesos Task ID 与Docker Container Name 的命名也是完全不一样的。 所以,使用cAdvisor+Prometheus是不合适的,可以使用Mesos-exporter + Prometheus方案,现在已经是Kubernetes的天下了,就不做演示了,