Prometheus¶
Prometheus的特性¶
前面在介绍篇幅我们已经对Prometheus做一些简单的概述以及架构特性简要描述,本小节开始对Prometheus的架构组件与其核心特性做一个完整的讲解。
Prometheus 特性
- 具有Metrics名称和key/value对标识的时间序列数据的多维数据模型
- 可以利用数据模型进行有效的警报和图形展示的查询语言
- 本地存储,不依赖分布式存储文件系统
- 通过 HTTP WEB 服务获取时间序列数据
- 可配置推送的方式来添加时间序列数据
- 支持通过服务发现或静态配置发现目标
- 多种图形、仪表板支持
Prometheus 核心组件
Prometheus Server:用于Scrap 目标 Job Metric、存储本地TSDB数据exporter:暴露本地Metrics给Prometheus,让Prometheus通过Pull模式Scrap目标Job指标数据pushgateway:推送网关,以Push模式将本地Metrics数据推送到PushGatewayalertmanager:警报组件,配置分组、警报发送源ad-hoc:过滤器,允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询
Prometheus 组件大多都是使用 Go语言 编写,所以很容易构建为静态的二进制文件用于部署。
以下是 Prometheus 官方提供的架构图,描述一些相关的生态系统组件:
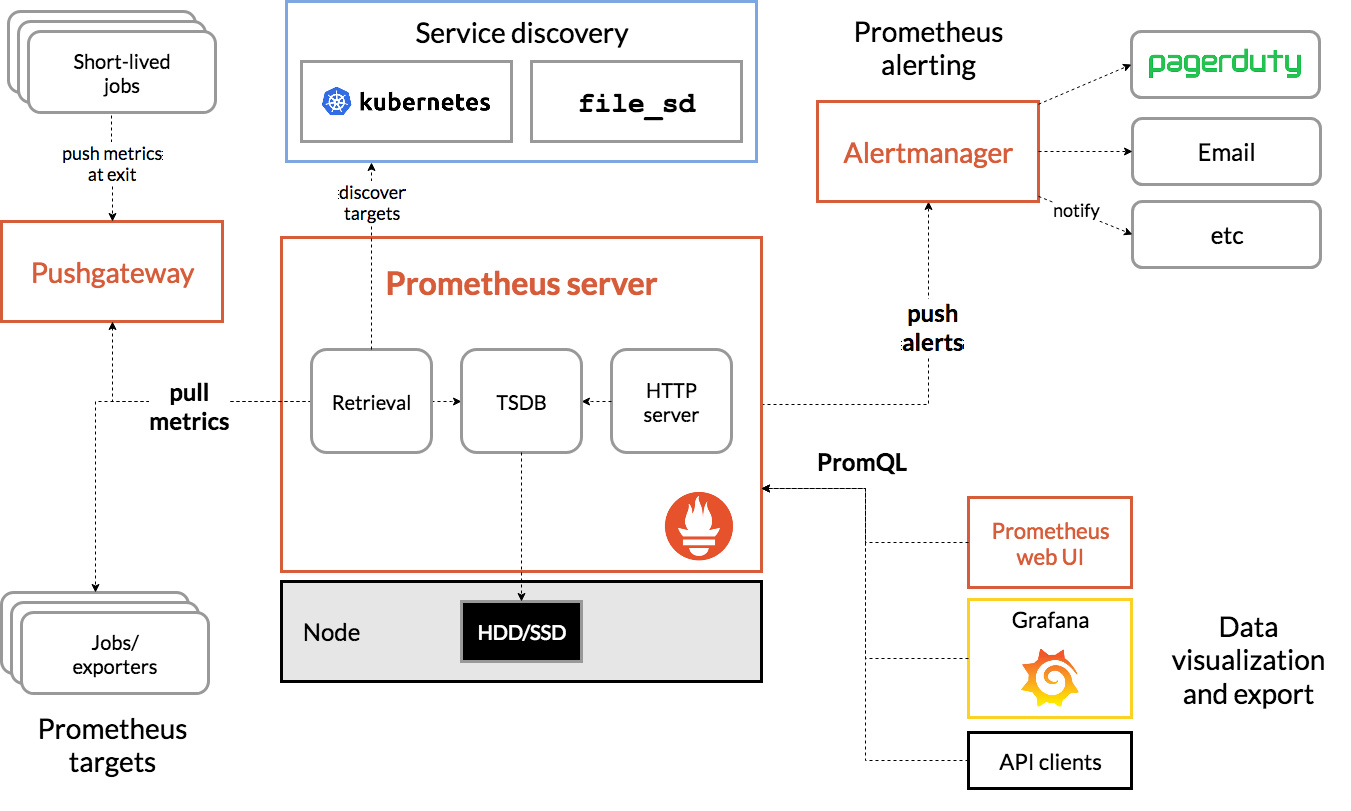
工作流程
Prometheus 整体工作流程相对比较简单,很容易理解,Prometheus 直接以 Pull 模式 Scrap 节点的指标数据或者在节点上通过 Push 模式推送数据到 Pushgateway 网关,用以被动获取指标数据,在本地存储所有的获取到的指标数据,并对这些数据进行一些整合处理,用以生成一些聚合数据或者报警信息,配合 Grafana 或者其他工具用来可视化图形展示。
为了方便对官方架构图的理解,在这里通过6个角度来解释Prometheus架构
-
对于短时间存活的目标Job以及因特殊环境需求而网络不可达的目标Job,可以通过push的模式推送指标数据到pushgateway组件
-
大部分常规的目标Job都是通过Prometheus Server 以
Pull模式来获取目标Job中Node_exporter组件收集的指标数据 -
针对Kubernetes或者云的目标Job用自动发现来获取指标数据,比如
Kubernetes利用kubernetes_sd_config做自动发现,AWS利用ec2_sd_config或Consul自动发现等 -
所有获取的的指标数据都存储在Prometheus Server中的本地的TSDB时序数据库中,通过
HTTP接口暴露给需要查询的WEB或者图形展示工具 -
Alertmanager警报组件可以单独部署,也支持集群模式,同时支持通过定义的分组推送到不同的媒介:Email、Webhook(Dingtalk、Wechat)、Slack等
-
可以使用PromQL通过Prometheus自带的WEB UI聚合查询,也可以使用Prometheus作为数据源使用其他图形化展示工具用以多维图形展示,同时支持RESTFul API接口查询;