Operator概述
近几年,云计算、分布式计算的发展异常迅速,其中Docker、Kubernetes、Prometheus等开源软件尤为显著,极大的推动了云计算的发展。本章首先先开始讲Prometheus是如何监控Kubernetes,介绍Prometheus Operator组件。 通过本章可以学习Kubernetes与Operator的优势是什么,以及我们为什么要用Operator。
Prometheus与 Kubernetes的完美结合¶
Kubernetes是基于Docker的开源容器集群管理系统,为容器化的应用提供资源调度、部署、运行、服务发现、自动扩容缩容、监控等一整套功能特性,因为容器本身可移植,所以Kubernetes容器集群能跑在私有云、公有云以及混合云上。 对于Kubernetes的细节就不过多的阐述了,如果想了解更多,请去看下阳明大佬的 Kubernetes 进阶训练营 课程。 我们这里主要讲Prometheus与Kubernetes的如何结合、监控与警报,言归正传,由于Kubernetes的底层是原生Docker技术进行管理,这也就铸就了Docker和Kubernetes是云原生时代的基石,那么Prometheus也就随之成为了云原生监控不可缺少的神器, 由于其天然性,在设计监控系统之处就是为了Kubernetes而生,后续的发展中也支持了各种平台以及社区的活跃涌现了更多的exporter。
什么是Kubernetes Operator¶
在Kubernetes的支持下,管理与缩容应用以及API服务都变的简单了,因为这些应用首先必须是无状态的,直接使用Deployment的Kubernetes API对象就可以无需附加操作的情况下,对应用进行缩容与故障恢复。
但是对于DB、Cache、带会话机制的有状态服务应用,这就是个问题了。这些服务应用需要对其有更深一层的了解,针对性的进行缩容与升级,同时要保证数据的完整性、一致性以及安全性。因此我们需要这些应用的相关信息直接定义成代码的方式,借助Kubernetes的API能力, 正确运行和管理更为复杂的应用。
Operator 其实就是将运维人员对软件操作的知识给代码化,同时利用Kubernetes强大的抽象逻辑来管理大规模的软件应用。
Operator 使用CRD(CustomResourceDefinition)对Kubernetes的API机制进行扩展,来创建、配置与管理应用。
当前CoreOS依靠社区力量创建了众多的 Operator,详情请参考:https://operatorhub.io/。
Prometheus Operator¶
Prometheus Operator 是为了 Kubernetes 服务和 Prometheus实例的集成部署和管理提供了简单的监控资源定义。
安装完成以后,Prometheus Operator的功能:
| 状态 | 描述 |
|---|---|
创建、销毁 |
在Kubernetes NS中更容易去管理一个Prometheus的实例,创建于销毁 |
配置 |
定义Prometheus的基础信息,比如 Kubernetes的本地资源的 version retention policies replicas等 |
Target Service |
通过标签定义,自动发现、生成监控 target 配置,简化配置。 |
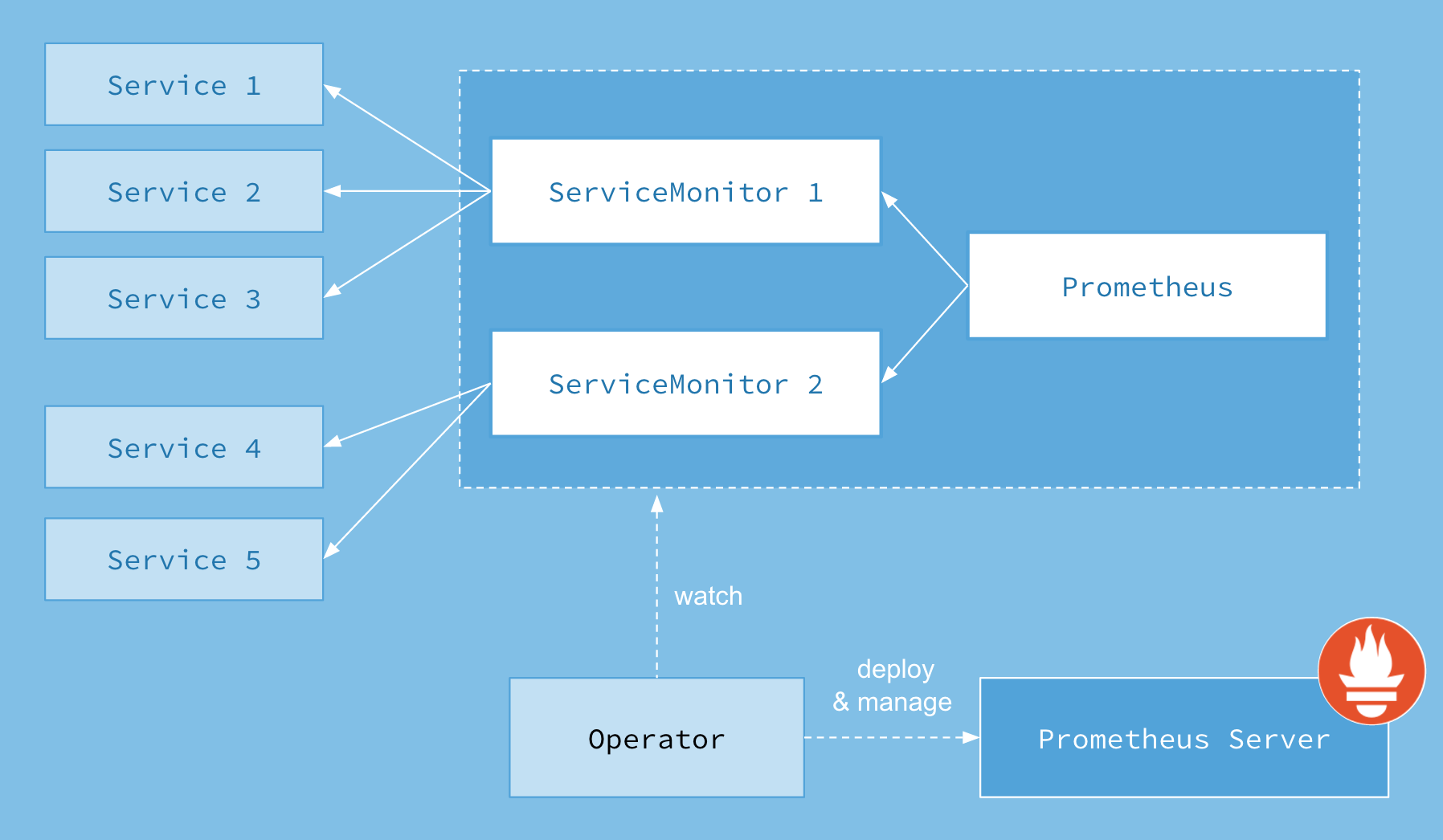
上图的各个组件以不同的资源方式运行在 Kubernetes 集群中,各自负责各自的功能。
| 组件 | 描述 |
|---|---|
Operator |
其实就是Prometheus在当前k8s中的整个控制中心,Operator资源会根据CRD来管理和部署Prometheus Server,同时监控自定义资源事件的变化来做对应的操作。 |
Prometheus |
Prometheus 资源是声明式的描述 Prometheus 部署的定义状态 |
Prometheus Server |
Operator 根据自定义资源当中的Prometheus类型中定义的内容来部署的Prometheus Server集群,可以理解为是用来管理Prometheus Server 的 StatefulSets 资源。 |
ServiceMonitor |
ServiceMonitor 也是一个自定义资源,用于描述一组Prometheus需要监控的Target列表,通过标签来选择对应的Service Entpoint ,让Prometheus Server通过选择Service来采集指标信息。 |
Service |
Service 资源主要是用来声明哪些是需要提供给Prometheus Server监控的对象(node-exporter、coredns等),也就是关联Kubernetes集群中的Metrics Server Pod,提供给 ServiceMonitor 选择,让Prometheus Server来获取指标信息。 |
Alertmanager |
Alertmanager也是一个自定义资源类型,由Operator根据资源描述内容来部署、管理Alertmanager集群与配置 |
为什么要用 Prometheus Operator¶
首先,Prometheus是以Pull模式来采集相关指标信息的,但是在k8s中会因为pod的调度原因从而使IP频繁变化,人工维护必然会造成重复的工作量,虽然有DNS的自动发现,但是对于新增的一些资源还是认为介入的做一些相关的配置。
而Prometheus Operator是基于用户自定义的CRD资源对Kubernetes API 控制器的操作的实现:
-
使用具有RBAC权限的 Prometheus Operator 控制器去监听已经定义好与需要自定义资源的变化,从而完成对Prometheus Server自定义资源以及配置在Kubernetes集群中的自动化管理工作。
-
在k8s集群中使用
Deployment、DaemonSet,StatefulSets来管理应用配置,同时使用SVC、Ingress来管理应用的内部、外部访问,使用ConfigMap、Secret来管理应用配置。 -
在k8s集群中对这些资源的创建,更新,删除的动作都会被转换为事件,k8s的CM负责监听这些事件并触发相应的任务来满足用户的定义,这种方式我们成为声明式,用户只需要关心应用的最终状态,其它的全部通过k8s来完成,从而减少更多应用配置的复杂程度。
-
除了官方原生的 Resource 资源外,k8s还允许用户根据自己的需求定义资源,通过自定义Controller对k8s API的抽象扩展,无需二开k8s便可做到给k8s添加功能与对象。
-
因为SVC自身的负载均衡,监控k8s中的target对应的最小调度单元是每个SVC后面的pod,因此 Prometheus Operator 创建了对应的CRD: kind: ServiceMonitor,而在kind: ServiceMonitor需要声明也就是定义被监控的svc的label以及Metrics的url路径与ns。